
The Prolonged Descent Into the Cave of Search
Lessons Learned from the Frontier

Here’s The Thing
From my last post, you’ll know that I’ve been implementing a local semantic search layer onto my data. This was made possible by the new embeddings endpoint provided by OpenAI.
The initial results were promising, and though the experience was rough around the edges (~15 second searches for ~1000 documents), I could (and still do) see the immense potential of having localized semantic search stored on every person’s device.
But here’s the thing.
There are so. many. EDGE CASES.
Trust the Process
Here is the rough outline of how local semantic search works (note the key on the top left for my progress):
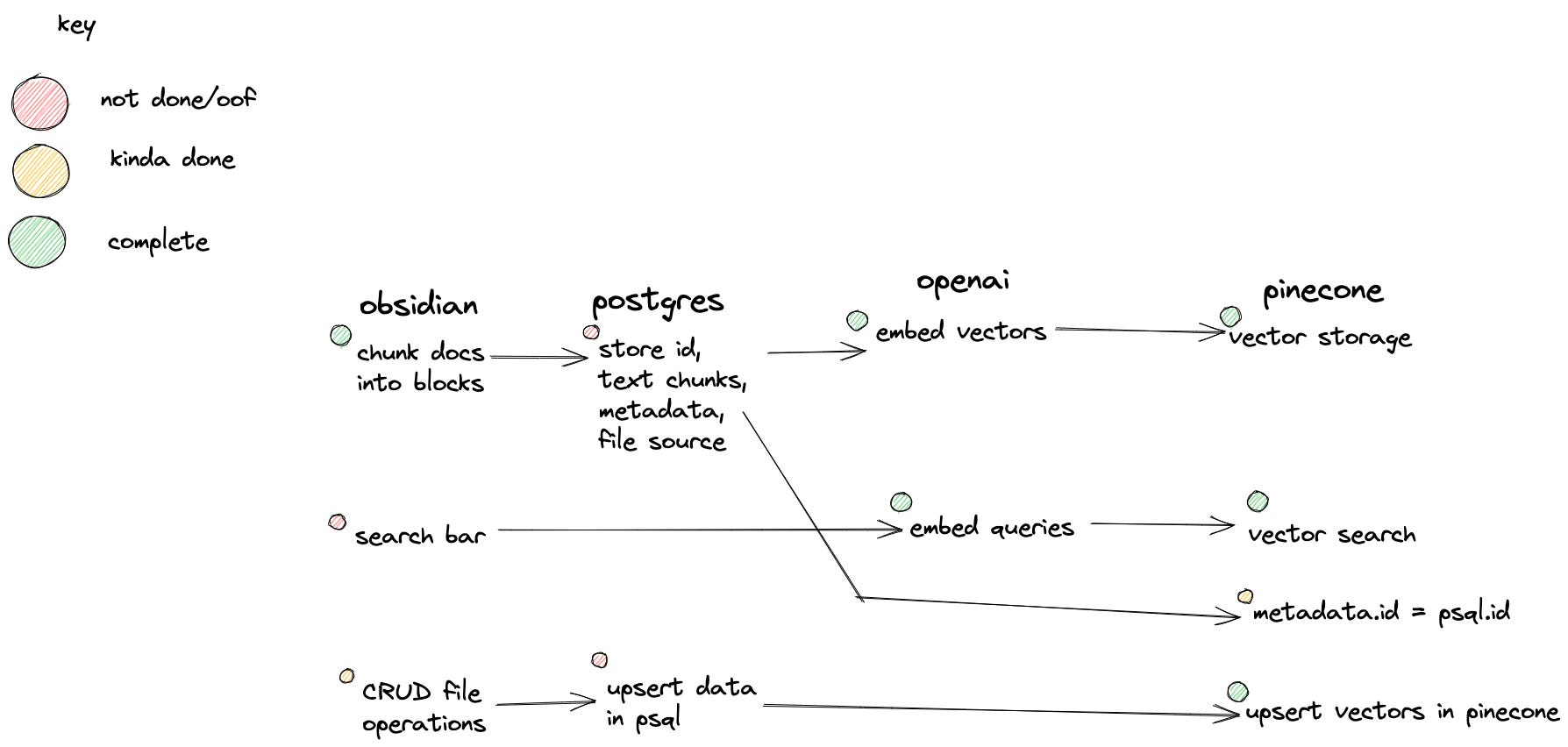
Obsidian - Where all the knowledge to be searched is stored. The “hub” of all information
Postgres - The database that is responsible for storing chunks, ids, and metadata like file data
OpenAI - Responsible for embedding text into vectors
Pinecone - A hosted vector storage and similarity solution using FAISS
Basically, I need all of these very different tools to work in harmony with each other if this project is to succeed. Currently, Obsidian wants nothing to do with PSQL, and the idea of writing cron jobs that maintain orchestrate this experience is a headache unto itself.
But the largest problem is much more sinister.
You see, the main benefit of semantic search is also its greatest weakness. The end user must decide what constitutes a document.
This may seem trivial, but let me promise you that it very much isn’t. When I’m searching for the word “mango” I can reasonably expect that typing “ma” or “man” or perhaps even “msn” (if the search system has good typo awareness) will return “mango”. But what if I type “tropical fruit in season in Spring”?
Therein lies the quandary. When committing text to a vector, one must decide when semantic similarity is a full grouping. Is it a word? a sentence? a paragraph? the entirety of War and Peace?
Currently, I’m using a brute force solution that leverages how I generally write, splitting ideas into small paragraphs.
But Obsidian is amazing, see? It stores videos, music, lists, code blocks, and more! Some are short, others are two page quotes that I took from a novel.
And that doesn’t begin to address the challenge of file upsertion, vector deletion, the feedback loops between duplicate blocks of text and the multitude of other problems I’m sure I haven’t even considered yet.
I may have to table this project for a while.
Ugh.
(if you have any experience with groupings in semantic search, please do let me know!)
In Other News
I splurged on a $1500 desk
I’ve been watching too many Everyday Carry type videos for a guy who only carries his phone and AirPods
I’ve been capturing my favorite stills from Demon Slayer S2 (spoiler alert, of course!)
I created a Python script that transcribes YouTube videos into Obsidian markdown
I realized that GitHub is my main social media
ars longa, vita brevis
Bram